
Econometrics: When to Pool, and when not to Pool?
Image via: https://immediate.net/
Introduction
Pooled econometrics can be powerful tool when used in the right way, but can have serious consequences for the accuracy of model results if applied incorrectly. And whilst they’ve been a feature of many Market Mix Modelling projects for the last two decades, there are still surprisingly few people who understand what they are, when you should use them, and when you shouldn’t. This article is a lay person’s guide to provide illumination to these questions.
What is a pooled econometric model?
First, it’s probably worth re-capping one of the defining features of a Market Mix Model. For the vast majority of cases these will be Time Series based. That is, all the data fed into the analysis will be at regular and sequential intervals in time, most likely weekly. This is driven by the fact that we often want to analyse media when the effect will not be instantaneous – so we need to be able to track its effect over a consistent period.
A pooled model combines Time Series and Cross Sectional data. Where a single Time Series model might look at total national sales for a specific product, the pooled model can be used to break down the sales at every point in time into a specific group. These cross sections or groups can take different forms, but they might for example be different retailers, different stores, or different consumer demographics.
Is a pooled econometric model better? The answer is it depends on how it is set up and applied, and what purpose you want it to achieve.
The main advantage and disadvantage of pooled models
The main advantage of a pooled model is speed when you want to model different splits of a KPI that have very similar behaviour.
To take an example, let’s suppose you want to understand the sales performance of an FMCG product sold in UK supermarkets. Since a pooled model allows you to apply it’s equations to all retailers simultaneously, such a set up may make it easier to understand the performance in Tesco, Sainsbury’s and Asda etc. The pooled model does this by applying the same response coefficients across each account (usually scaled for their size), so seasonal uplifts at Christmas will typically have a similar sized percentage uplift in Morisons and Waitrose in the pooled model. The advantage here is that you get a view of performance in each retailer, but it can be delivered faster than building separate equations for each retailer, and therefore potentially at lower cost.
Is there a disadvantage to doing this? The main one is that the default assumption in a pooled model is that behaviour will be the same in each and every cross section, which may not be true. It therefore depends on the application the econometrician is attempting to pool. For example, it would make no sense to build a pooled model across online sales and retail sales of the same product. One very obvious difference is that digital advertising will have a massively different effect on two routes to market, but other characteristics, such as different consumers and need states are likely to affect responses to a whole host of variables besides media – such as seasonality, price promotional offers, and competitor effects.
It should be noted pooled models do have some flexibility. Individual variables can be split out and separated so they have different effects in every cross section. However, if this is done for every variable in the model it collapses to produce exactly the same results as separate equations would do. In this case, the best case scenario is that there is no time and cost saving. In practice though it is likely to be worse, the analyst is likely to miss phenomenon unique to the cross sections that they would be more obvious if the equations were built separately.
Applications where pooling is and isn’t suitable
The following shows a guideline of where pooling should and shouldn’t be used:
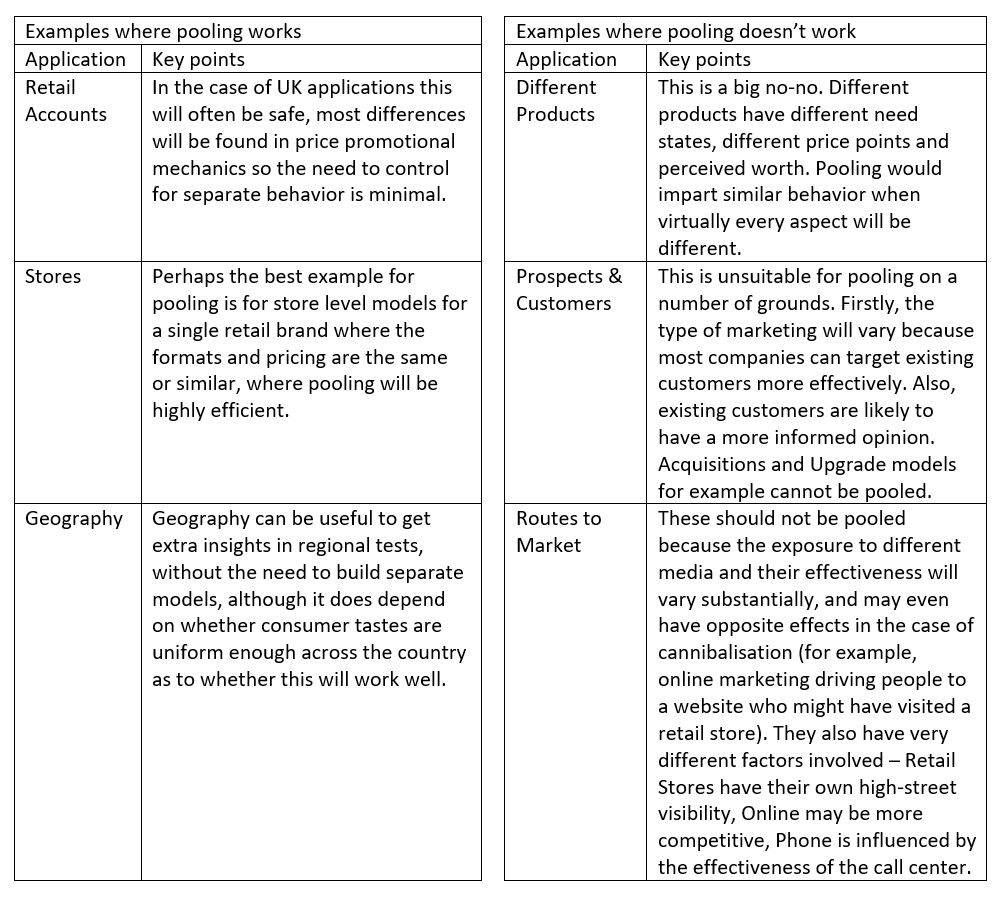
Other applications can be successful or not depending on the application. For example, customer demographic splits may be viable to pool, but it whether this is case will be contingent on how different the behaviour is.
Summary
This guide sheds some light on the common econometric pooled model – often not understood, and occasionally misused. We find that is useful and efficient at modelling across different brick-and-mortar retailers, individual stores, and geographies. However, across different products, customers versus prospects, and routes to market, it will do more harm than good, at best conferring no benefit and at worst degrading the robustness of model results.